


國(guó)產(chǎn) AI 最卷一夜!大模型黑馬 DeepSeek,、Kimi 硬剛 OpenAI o1,,實(shí)測(cè)體驗(yàn)到底有多強(qiáng)

趕在放假前,支棱起來的國(guó)產(chǎn) AI 大模型廠商井噴式發(fā)布了一大堆春節(jié)禮物,。
前腳 DeepSeek-R1 正式發(fā)布,,號(hào)稱性能對(duì)標(biāo) OpenAI o1 正式版,后腳 k1.5 新模型也正式登場(chǎng),,表示性能做到滿血版多模態(tài) o1 水平,。

如果再加上此前強(qiáng)勢(shì)登場(chǎng)的智譜 GLM-Zero,階躍星辰推理模型 Step R-mini,,星火深度推理模型 X1,,年末上大分的國(guó)產(chǎn)大模型拉開了真刀真槍的帷幕,也給以 OpenAI 為代表的海外模型狠狠上了一波壓力,。
- DeepSeek-R1 :在數(shù)學(xué),、代碼、自然語言推理等任務(wù)上,,性能比肩 OpenAI o1 正式版
- 月之暗面 k1.5:數(shù)學(xué),、代碼、視覺多模態(tài)和通用能力全面超越 GPT-4o 和 Claude 3.5 Sonnet,。
- 智譜 GLM-Zero:擅長(zhǎng)處理數(shù)理邏輯,、代碼和需要深度推理的復(fù)雜問題
- 階躍 Step-2 mini:極速響應(yīng),平均首字時(shí)延僅 0.17 秒,,還有 Step-2 文學(xué)大師版
- 星火 X1:數(shù)學(xué)能力亮眼,,有全面思考過程,,拿捏小學(xué)、初中,、高中,、大學(xué)全學(xué)段數(shù)學(xué)
井噴不是偶然的爆發(fā),而是積蓄已久的力量,,可以說,,國(guó)產(chǎn) AI 模型在春節(jié)前夕的突圍,將有望重新定義 AI 發(fā)展的世界坐標(biāo),。
昨晚率先發(fā)布的 DeepSeek-R1 現(xiàn)在已經(jīng)上架 DeepSeek 官網(wǎng)與 App,,打開就能用。
9.8 和 9.11 哪個(gè)大以及 Strawberry 里有幾個(gè) r 的難題在第一次測(cè)試中就順利過關(guān),,別看思維鏈略顯冗長(zhǎng),但正確答案事實(shí)勝于雄辯,。

面對(duì)弱智吧難題「跳多高才能跳過手機(jī)上的廣告」的拷問,, 響應(yīng)速度極快的 DeepSeek-R1 不僅能夠避開語言陷阱,還提供了不少規(guī)避廣告的的建議,,十分人性化,。

幾年前,有一道名為「如果昨天是明天,,今天就是星期五,,實(shí)際今天是星期幾」的邏輯推理題走紅網(wǎng)絡(luò),在面臨同樣問題的拷問后,,OpenAI o1 給出的答案是周日,,DeepSeek-R1 則是周三。
但就目前來看,,至少 DeepSeek-R1 更靠近答案,。

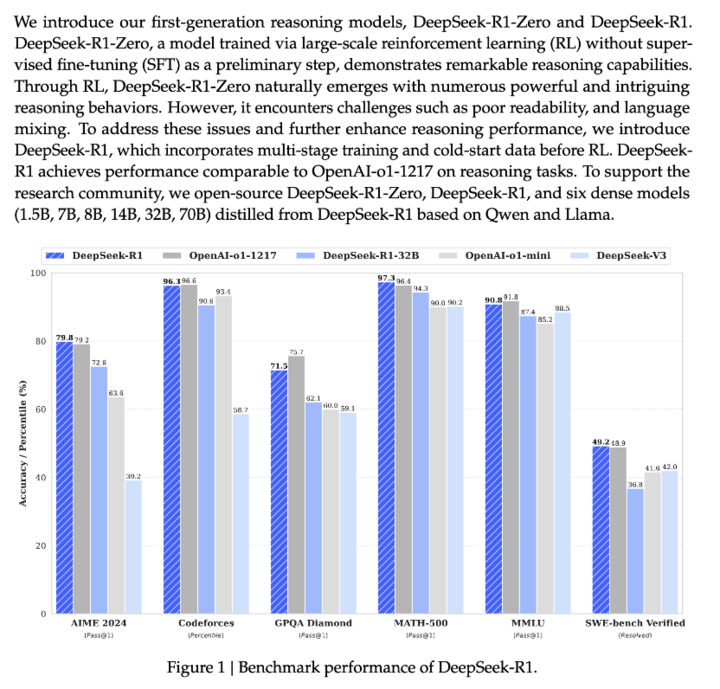
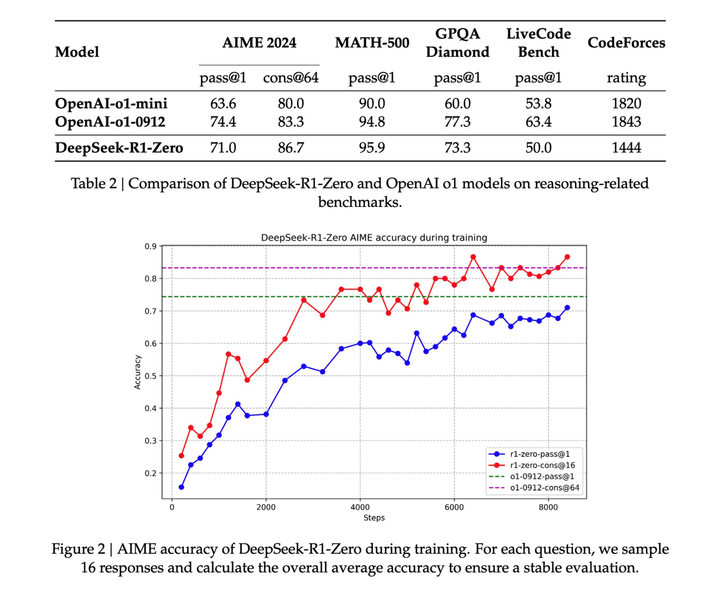
據(jù)介紹,,DeepSeek-R1 在數(shù)學(xué)、代碼,、自然語言推理等任務(wù)上,,性能比肩 OpenAI o1 正式版,理論上更偏向于理科生,。
正好趕上小紅書上中美兩國(guó)網(wǎng)友在友好交流數(shù)學(xué)作業(yè),,我們也讓 DeepSeek-R1 幫忙解疑答惑。
插個(gè)冷知識(shí),,上回 DeepSeek 海外爆火時(shí)就有網(wǎng)友發(fā)現(xiàn),,其實(shí) DeepSeek 也支持圖片識(shí)別,我們可以直接讓模型分析美國(guó)網(wǎng)友上傳的試卷圖片,。
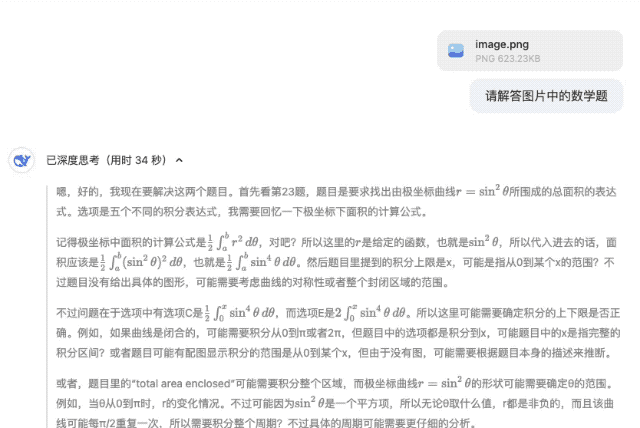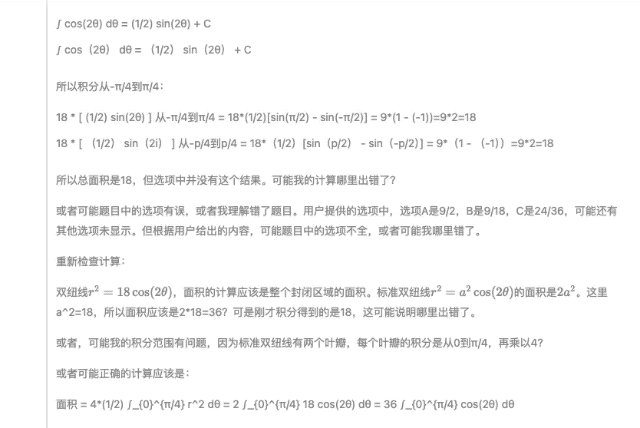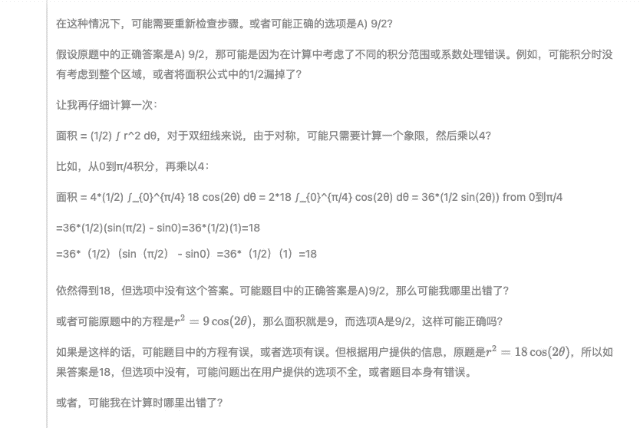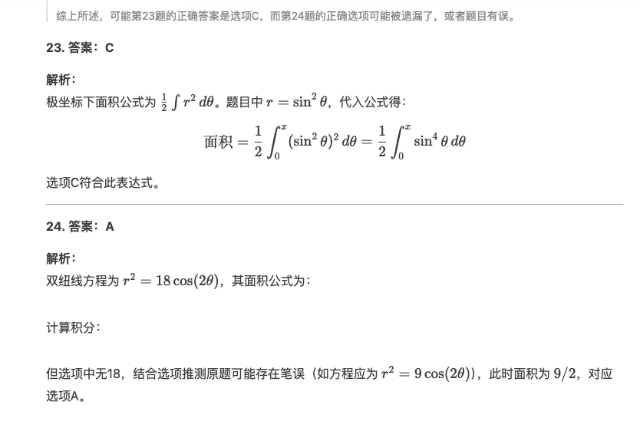
攏共兩道題,,第一道題選 C,第二道題選 A,,并且,,「自信滿滿」的 DeepSeek-R1 推測(cè)第二道題原題的選項(xiàng)中無 18,結(jié)合選項(xiàng)推測(cè)原題可能存在筆誤(如方程應(yīng)為 r2=9cos?(2θ)r2=9cos(2θ)),。
在隨后的線性代數(shù)證明題中,,,DeepSeek-R1 提供的證明步驟邏輯嚴(yán)謹(jǐn),,同一道題目還提供了多種驗(yàn)證方法,,展現(xiàn)出深厚的數(shù)學(xué)功底。
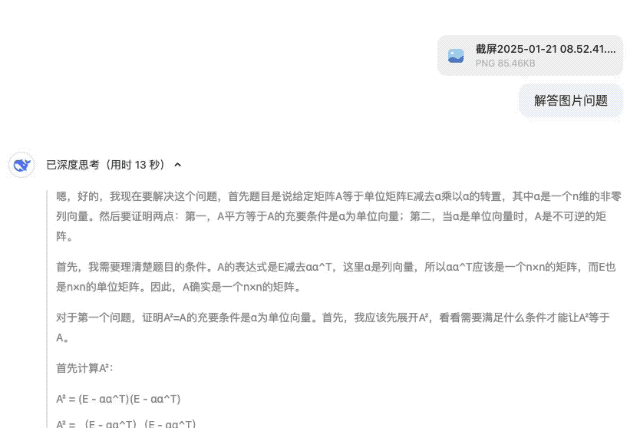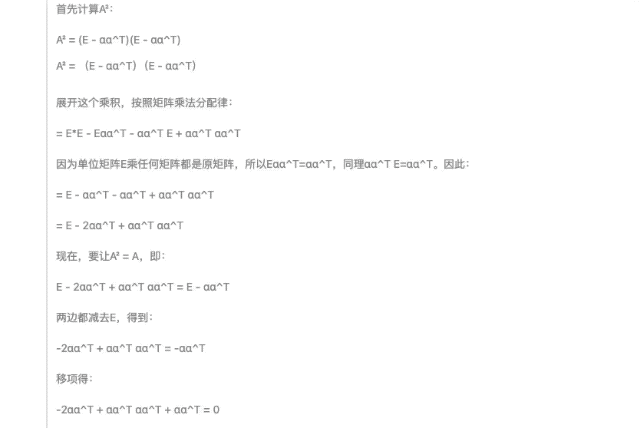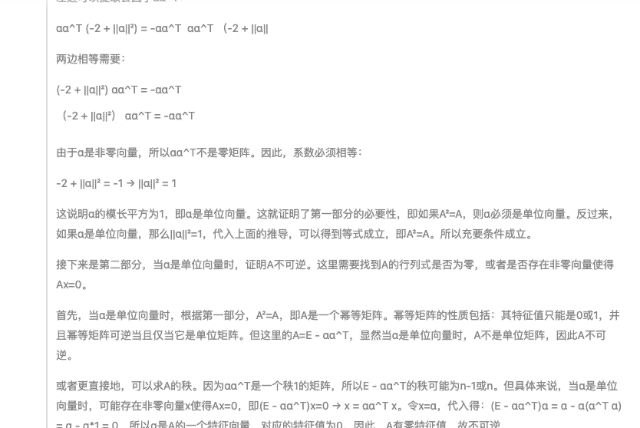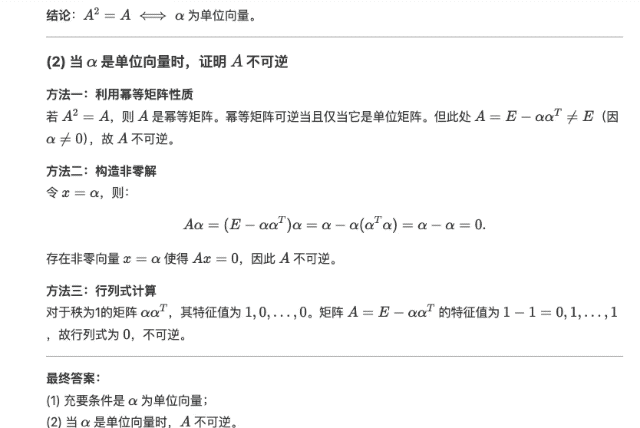
始于性能,陷于成本,,忠于開源,。 DeepSeek-R1 正式發(fā)布之后,也同步開源模型權(quán)重,。我宣布,,來自中國(guó)東方的 DeepSeek 才是真正的 OpenAI。
據(jù)悉,,DeepSeek-R1 遵循 MIT License,,允許用戶通過蒸餾技術(shù)借助 R1 訓(xùn)練其他模型。DeepSeek-R1 上線 API,,對(duì)用戶開放思維鏈輸出,,通過設(shè)置 model=’deepseek-reasoner’ 即可調(diào)用。
并且,,DeepSeek-R1 訓(xùn)練技術(shù)全部公開,,論文鏈接指路?? https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
DeepSeek-R1 技術(shù)報(bào)告里提到一個(gè)值得關(guān)注的發(fā)現(xiàn),那就是 R1 zero 訓(xùn)練過程里出現(xiàn)的「aha moment(頓悟時(shí)刻)」,。
在模型的中期訓(xùn)練階段,DeepSeek-R1-Zero 開始主動(dòng)重新評(píng)估初始解題思路,,并分配更多時(shí)間優(yōu)化策略(如多次嘗試不同解法),。換句話說,通過 RL 框架,,AI 可能自發(fā)形成類人推理能力,,甚至超越預(yù)設(shè)規(guī)則的限制。
并且這也將有望為開發(fā)更自主,、自適應(yīng)的 AI 模型提供方向,,比如在復(fù)雜決策(醫(yī)療診斷、算法設(shè)計(jì))中動(dòng)態(tài)調(diào)整策略,。正如報(bào)告所說,,「這一時(shí)刻不僅是模型的『頓悟時(shí)刻』,也是研究人員觀察其行為時(shí)的『頓悟時(shí)刻』,?!?/p>

除了主打的大模型,DeepSeek 的小模型同樣實(shí)力不俗,。
DeepSeek 通過對(duì) DeepSeek-R1-Zero 和 DeepSeek-R1 這兩個(gè) 660B 模型的蒸餾,,開源了 6 個(gè)小模型。其中,,32B 和 70B 型號(hào)在多個(gè)領(lǐng)域達(dá)到了 OpenAI o1-mini 的水準(zhǔn),。
并且,,僅 1.5B 參數(shù)大小的 DeepSeek-R1-Distill-Qwen-1.5B 在數(shù)學(xué)基準(zhǔn)測(cè)試中超越了 GPT-4o 和 Claude-3.5-Sonnet,AIME 得分為 28.9%,,MATH 得分為 83.9%,。
HuggingFace鏈接:https://huggingface.co/deepseek-ai
在 API 服務(wù)定價(jià)方面,號(hào)稱 AI 屆拼多多的 DeepSeek 也采用了靈活的階梯定價(jià):每百萬輸入 tokens 根據(jù)緩存情況收費(fèi) 1-4 元,,輸出 tokens 統(tǒng)一 16 元,,再次大幅降低開發(fā)使用成本。
DeepSeek-R1 發(fā)布以后,,也再次在海外 AI 圈引起轟動(dòng),,收獲了大量「自來水」。其中,,博主 Bindu Reddy 更是給 Deepseek 冠上了開源 AGI 和文明的未來之稱,。
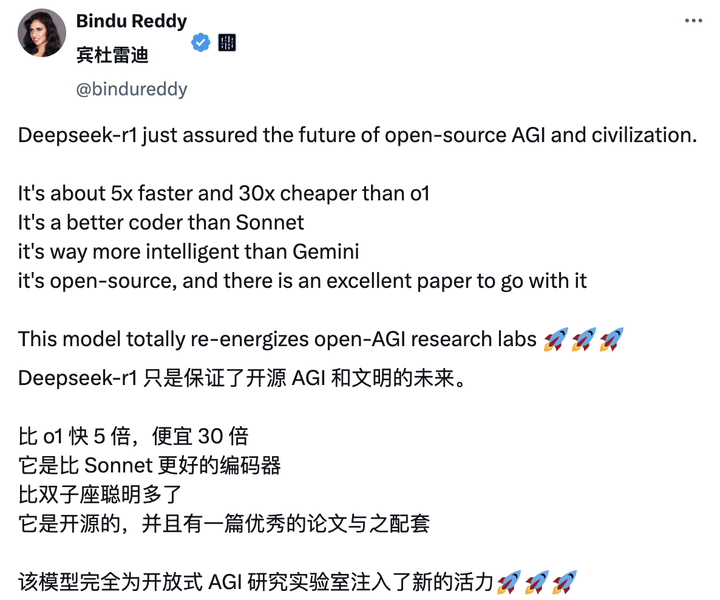
出色的評(píng)價(jià)源于模型在網(wǎng)友的實(shí)際應(yīng)用中出色的表現(xiàn)。從 30 秒詳細(xì)闡釋勾股定理,,到 9 分鐘深入淺出地講解量子電動(dòng)力學(xué)原理并提供可視化呈現(xiàn),。DeepSeek-R1 沒有任何差錯(cuò)。
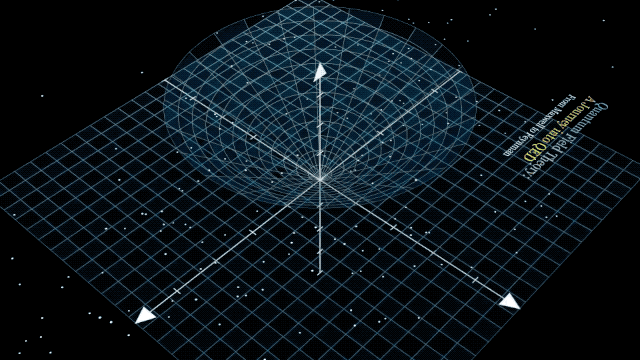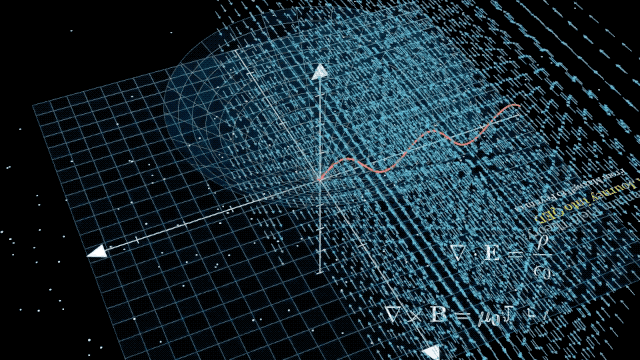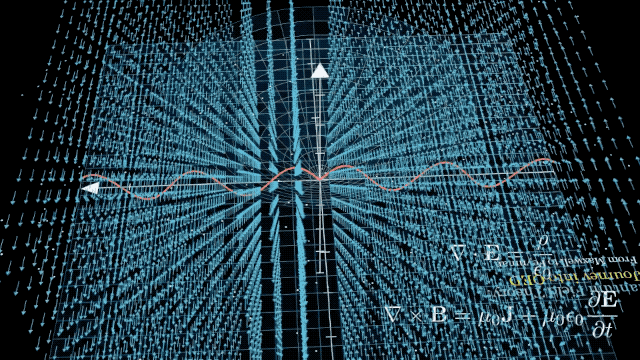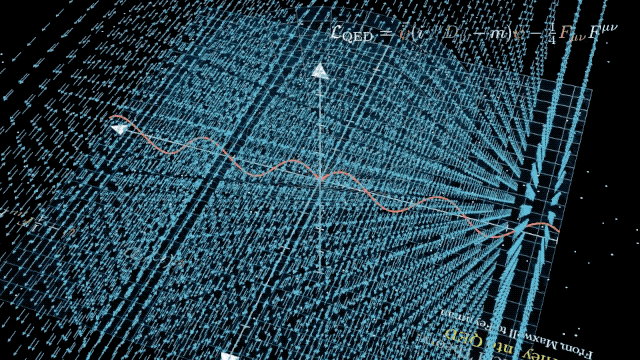
甚至也有網(wǎng)友特別欣賞 DeepSeek-R1 所展示的思維鏈,,認(rèn)為「像極了人類的內(nèi)心獨(dú)白,,既專業(yè)又可愛」。
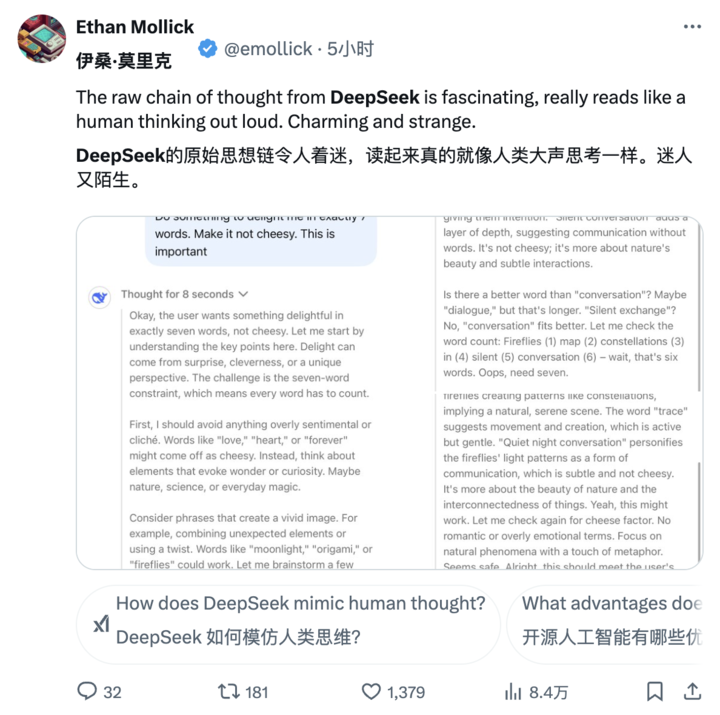
英偉達(dá)高級(jí)研究科學(xué)家 Jim Fan 對(duì) DeepSeek-R1 給予了高度評(píng)價(jià),。他指出這代表著非美國(guó)公司正在踐行 OpenAI 最初的開放使命,,通過公開原始算法和學(xué)習(xí)曲線等方式實(shí)現(xiàn)影響力,順便還內(nèi)涵了一波 OpenAI,。
DeepSeek-R1 不僅開源了一系列模型,,還披露了所有訓(xùn)練秘密。它們可能是首個(gè)展示 RL 飛輪重大且持續(xù)增長(zhǎng)的開源項(xiàng)目,。
影響力既可以通過『ASI 內(nèi)部實(shí)現(xiàn)』或『草莓計(jì)劃』等傳說般的項(xiàng)目實(shí)現(xiàn),,也可以簡(jiǎn)單地通過公開原始算法和 matplotlib 學(xué)習(xí)曲線來達(dá)成。
在深入研究論文后,,Jim Fan 特別強(qiáng)調(diào)了幾個(gè)關(guān)鍵發(fā)現(xiàn):
完全由強(qiáng)化學(xué)習(xí)驅(qū)動(dòng),,沒有任何 SFT(監(jiān)督微調(diào))。讓人聯(lián)想到 AlphaZero——從零開始掌握圍棋,、將棋和國(guó)際象棋,,而不是先模仿人類大師的棋步,。這是論文中最關(guān)鍵的發(fā)現(xiàn)。 使用硬編碼規(guī)則計(jì)算的真實(shí)獎(jiǎng)勵(lì),。
避免使用強(qiáng)化學(xué)習(xí)容易破解的學(xué)習(xí)獎(jiǎng)勵(lì)模型,。 隨著訓(xùn)練進(jìn)展,模型的思考時(shí)間逐步增加——這不是預(yù)先編寫的程序,,而是一種涌現(xiàn)特性,! 自我反思和探索行為的涌現(xiàn)。
GRPO 替代了 PPO:它移除了 PPO 的評(píng)論網(wǎng)絡(luò),,改用多個(gè)樣本的平均獎(jiǎng)勵(lì),。這是一種減少內(nèi)存使用的簡(jiǎn)單方法。需要注意的是,,GRPO 是作者團(tuán)隊(duì)提出的一種創(chuàng)新方法,。
整體來看,這項(xiàng)工作展示了強(qiáng)化學(xué)習(xí)在大規(guī)模場(chǎng)景中實(shí)際應(yīng)用的開創(chuàng)性潛力,,并證明某些復(fù)雜行為可以通過更簡(jiǎn)單的算法結(jié)構(gòu)實(shí)現(xiàn),,而無需進(jìn)行繁瑣的調(diào)整或人工干預(yù)。
一圖勝千言,,更明顯的對(duì)比如下:
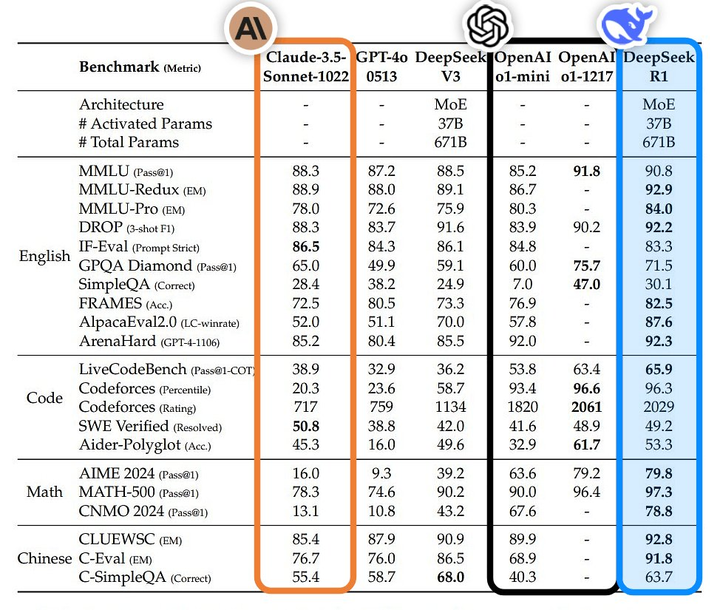
就這樣,,DeepSeek 再次在海內(nèi)外完成二次爆火,不僅是一次技術(shù)突破,,更是中國(guó)乃至世界的開源精神的勝利,,也因此收獲了不少海外忠實(shí)擁躉。
同一天上線的還有 Kimi v1.5 多模態(tài)思考模型,。
自去年 11 月 Kimi 推出 k0-math 數(shù)學(xué)模型,12 月發(fā)布 k1 視覺思考模型以來,,這是第三次 K 系列的重要上新,。
在短思考模式(short-CoT)的較量中,Kimi k1.5 展現(xiàn)出壓倒性優(yōu)勢(shì),,其數(shù)學(xué),、代碼、視覺多模態(tài)和通用能力全面超越了行業(yè)翹楚 GPT-4o 和 Claude 3.5 Sonnet,。
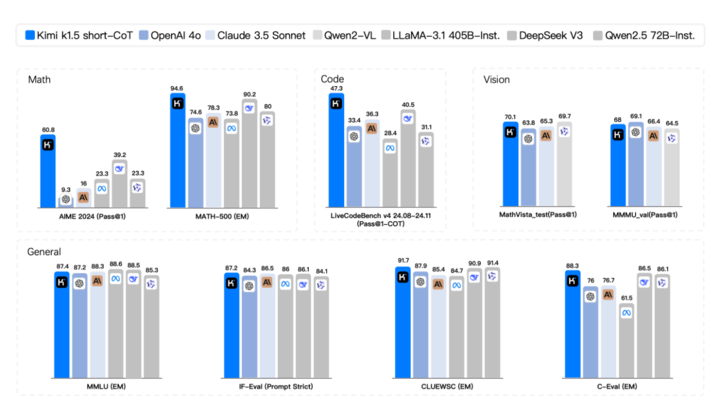
在長(zhǎng)思考模式(long-CoT)的競(jìng)爭(zhēng)中,,Kimi k1.5 的代碼和多模態(tài)推理能力已經(jīng)比肩 OpenAI o1 正式版,成為全球范圍內(nèi)首個(gè)在 OpenAI 之外實(shí)現(xiàn) o1 級(jí)別多模態(tài)推理性能的模型,。
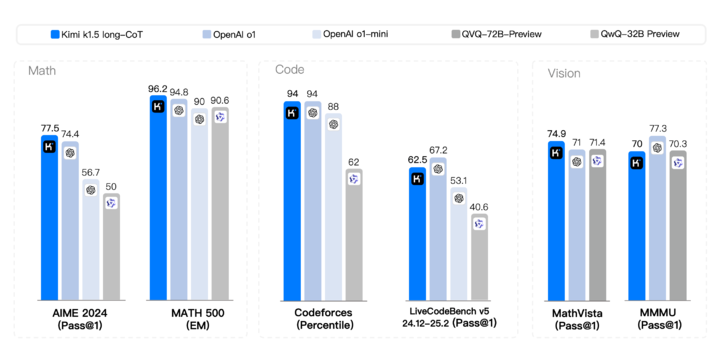
伴隨著模型的重磅發(fā)布,,Kimi 還首次公開了完整的模型訓(xùn)練技術(shù)報(bào)告。
GitHub 鏈接:https://github.com/MoonshotAI/kimi-k1.5
據(jù)官方介紹,,k1.5 模型的核心技術(shù)突破主要體現(xiàn)在四個(gè)關(guān)鍵維度:
- 長(zhǎng)上下文擴(kuò)展,。我們將 RL 的上下文窗口擴(kuò)展到 128k,,并觀察到隨著上下文長(zhǎng)度的增加,性能持續(xù)提升,。我們的方法背后的一個(gè)關(guān)鍵思想是,,使用部分展開(partial rollouts)來提高訓(xùn)練效率——即通過重用大量先前的軌跡來采樣新的軌跡,避免了從頭開始重新生成新軌跡的成本,。我們的觀察表明,,上下文長(zhǎng)度是通過 LLMs 持續(xù)擴(kuò)展RL的一個(gè)關(guān)鍵維度。
- 改進(jìn)的策略優(yōu)化,。我們推導(dǎo)出了long-CoT的 RL 公式,,并采用在線鏡像下降的變體進(jìn)行穩(wěn)健的策略優(yōu)化。該算法通過我們的有效采樣策略,、長(zhǎng)度懲罰和數(shù)據(jù)配方的優(yōu)化進(jìn)一步得到改進(jìn),。
- 簡(jiǎn)潔的框架。長(zhǎng)上下文擴(kuò)展與改進(jìn)的策略優(yōu)化方法相結(jié)合,,為通過LLMs學(xué)習(xí)建立了一個(gè)簡(jiǎn)潔的RL框架,。由于我們能夠擴(kuò)展上下文長(zhǎng)度,學(xué)習(xí)到的 CoTs 表現(xiàn)出規(guī)劃,、反思和修正的特性,。增加上下文長(zhǎng)度的效果是增加了搜索步驟的數(shù)量。因此,,我們展示了可以在不依賴更復(fù)雜技術(shù)(如蒙特卡洛樹搜索,、價(jià)值函數(shù)和過程獎(jiǎng)勵(lì)模型)的情況下實(shí)現(xiàn)強(qiáng)大的性能。
- 多模態(tài)能力,。我們的模型在文本和視覺數(shù)據(jù)上聯(lián)合訓(xùn)練,,具有聯(lián)合推理兩種模態(tài)的能力。該模型數(shù)學(xué)能力出眾,,但由于主要支持LaTeX等格式的文本輸入,,依賴圖形理解能力的部分幾何圖形題則難以應(yīng)對(duì)。
k1.5 多模態(tài)思考模型的預(yù)覽版將陸續(xù)灰度上線官網(wǎng)和官方 App,。值得一提的是,,k1.5 的發(fā)布同樣在海外引起了巨大的反響。有網(wǎng)友對(duì)這個(gè)模型不吝贊美之詞,,讓海外見證了中國(guó) AI 實(shí)力的崛起,。
實(shí)際上,年末國(guó)內(nèi)推理模型的密集發(fā)布絕非偶然,,這是 OpenAI 去年 10 月發(fā)布 o1 模型在全球 AI 領(lǐng)域掀起的漣漪終于傳導(dǎo)至中國(guó)的顯著標(biāo)志,。短短數(shù)月從追趕到比肩,國(guó)產(chǎn)大模型用行動(dòng)證明了中國(guó)速度,。
菲爾茲獎(jiǎng)得主,、數(shù)學(xué)天才陶哲軒曾認(rèn)為這類推理模型或許只需再經(jīng)過一兩輪迭代與能力提升,,就能達(dá)到「合格研究生」的水準(zhǔn)。而 AI 發(fā)展的遠(yuǎn)景遠(yuǎn)不止于此,。

當(dāng)前,,我們正見證著 AI 智能體一個(gè)關(guān)鍵的轉(zhuǎn)型時(shí)刻。從單純的「知識(shí)增強(qiáng)」向「執(zhí)行增強(qiáng)」跨越,,開始主動(dòng)參與決策制定和任務(wù)執(zhí)行的過程,。與此同時(shí),AI 也在突破單一模態(tài)的限制,,向著多模態(tài)融合的方向快速演進(jìn),。當(dāng)執(zhí)行遇上思考,AI才真正具備了改變世界的力量,。
基于此,,像人一樣思考的模型正在為 AI 的實(shí)際落地開辟更多可能性。
表面上看,,年末這波國(guó)內(nèi)推理模型的密集涌現(xiàn),,表面上看或許帶有「中國(guó)式跟隨者創(chuàng)新」的影子,但深入觀察就會(huì)發(fā)現(xiàn),,無論是在開源策略的深度,,還是在技術(shù)細(xì)節(jié)的精確度上,中國(guó)廠商依然走出了一條獨(dú)具特色的發(fā)展道路,。
轉(zhuǎn)載請(qǐng)注明來自浙江中液機(jī)械設(shè)備有限公司 ,,本文標(biāo)題:《國(guó)產(chǎn) AI 最卷一夜!大模型黑馬 DeepSeek,、Kimi 硬剛 OpenAI o1,,實(shí)測(cè)體驗(yàn)到底有多強(qiáng)》

昆明小區(qū)房?jī)r(jià) 最新消息,,昆明小區(qū)房?jī)r(jià)實(shí)時(shí)動(dòng)態(tài)揭曉

杭州車床工最新招聘信息,,杭州車床工招聘啟事

清遠(yuǎn)最新招聘信息網(wǎng),一站式求職服務(wù)平臺(tái),,助您輕松找到理想工作,,清遠(yuǎn)一站式求職招聘平臺(tái),輕松尋理想職位

中山儋州疫情最新消息,中山儋州疫情最新更新

豐城招聘宣傳員,,最新崗位信息來襲,,快來加入我們!,,豐城熱招宣傳員,,新崗位等你來挑戰(zhàn)!

最新的手機(jī)動(dòng)漫網(wǎng)頁,最新手機(jī)動(dòng)漫網(wǎng)頁潮流概覽

廊坊招聘保安員最新信息,廊坊最新保安員招聘信息發(fā)布

福州最新的永輝在哪兒,,福州最新永輝超市位置揭秘
 浙ICP備18034934號(hào)-2
浙ICP備18034934號(hào)-2 浙ICP備18034934號(hào)-2
浙ICP備18034934號(hào)-2
還沒有評(píng)論,,來說兩句吧...